

Содержание:
- Что такое веб скрапинг.
- Как устроен web.
- Парсинг
- Преимущества и недостатки.
- Заключение.
Что такое веб скрапинг?
Скрапинг — это процесс, возможность которого позволяет получить набор конкретных данных, которые нужны пользователю из практически любого web ресурса в автоматическом режиме! Простыми словами — это некий алгоритм который ходит по сайту и собирает информацию также, как человек.
Скрапинг используется во многих направлениях:
В бизнесе — когда необходимо собрать какую либо информацию о конкурентах из простора интернета.
В аналитике — когда необходимо проанализировать какие-либо данные.
В Data Science, когда нужно собрать огромное количество данных из интернета когда требуется обучить модель нейронной сети.
Специалистам, чья работа связана с SEO, дизайном, копирайтингом, а так-же блогерам и контент менеджерам.
Процесс скрапинга:
Сбор URL – адресов: Определяем страницы которые необходимо скандировать.
Извлечение HTML – кода: Формирование алгоритма HTTP – запроса для получения содержимого страницы.
Парсинг данных: Применение библиотеки языка программирования для извлечения нужной информации из HTML – кода.
Сохранение данных: Экспорт извлеченных данных в удобный формат.
** HTML: язык гипертекстовой разметки сайта.
** HTTP: Формат запроса к HTML странице сайта.
Как устроен web?
Все, что находится в сети интернет, имеет одинаковую систему отображения информации, которую мы видим в браузере:
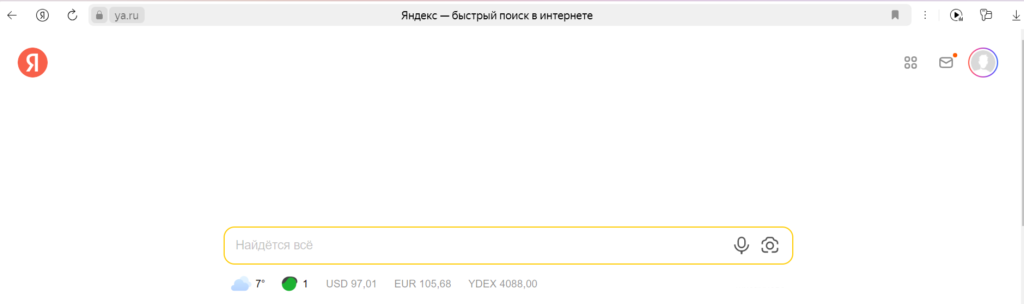
Но это только то, что видим мы — визуальная часть web страницы. Весь этот визуал мы получаем за счет обработки клиентской части нашего браузера, но если убрать эту обработку, та же страница будет выглядеть иначе:
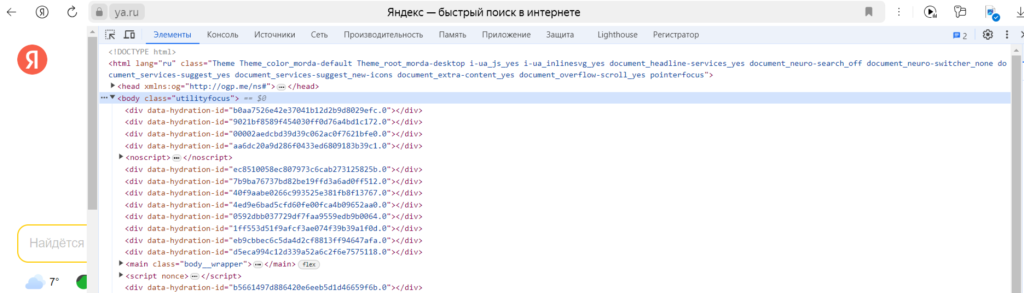
Как видно, страница не имеет визуального представления, но имеет иерархическую структуру, эту самую иерархию задает HTML – язык гипертекстовой разметки. С помощью него браузер понимает в каком месте и что нам показывать.
Если развернуть любой блок с этой структурой, то сразу видно какую информацию он несет:

Да видно блоки и информацию в них, но сам функционал находится на сервере и выглядит это в упрощенном варианте следующим образом:
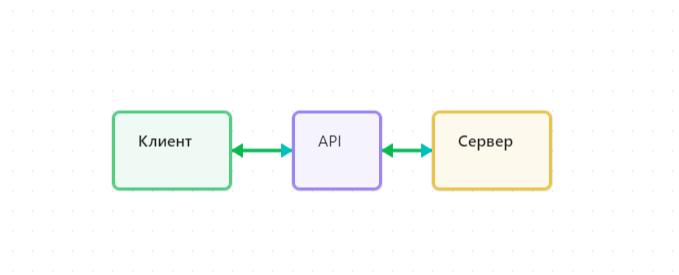
Клиент — это представление, визуальная часть web ресурса.
API – это возможность взаимодействовать с сервером ресурса.
Сервер — это сам мозг web ресурса который обеспечивает функционал.
Как работает парсинг?
Как правило, возможности обращаться к серверу напрямую — у нас быть не должно. Кроме доступного функционала в визуальной части — клиенте. Но если есть возможность использовать открытый API текущего ресурса, то доступ к запросам на сервер может быть осуществлен и без использования клиентской части, но функционал API прописан в настройках его подключения, и имеет ряд ограничений, либо не бесплатен!
Если говорить об этом в теме web скрапинга — если есть клиентская часть, то она должна отправлять запросы на сервер, а если она отправляет их, то мы можем узнать в каком формате и куда эти запросы идут!
Например введем в поисковую строку Яндекса слово «привет», браузер выдаст нам контент согласно нашему слову, но перед тем как он это сделает, будет передан GET — запрос с нашим словом «привет» на сервер, для его обработки и отправки результата. То, что клиент отправляет на сервер выглядит так:

Тут мы видим куда идет запрос, и какой сам запрос. В ссылке есть строка — text=%D0%BF%D1%80%D0%B8%D0%B2%D0%B5%D1%82 , эта строка и есть наше слово «привет» в кодировке. Если это все так работает, то мы можем просто подставлять слова и отправлять их по этому же адресу?
Берем весь URL запроса, кодируем по тому же принципу слово «получилось» и подставляем в ссылку, результат перед нами:
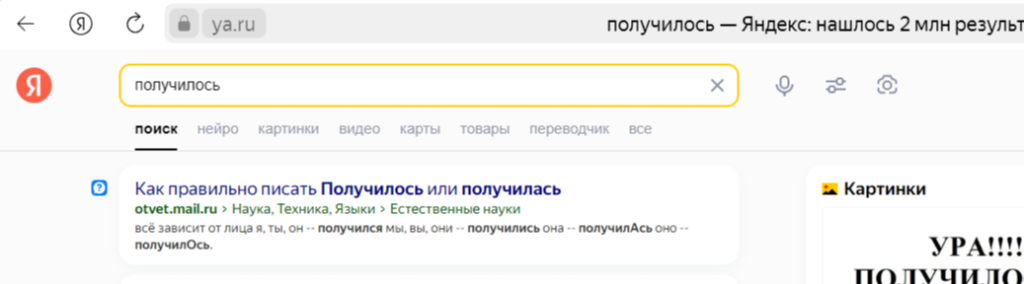
Все что мы сейчас сделали — это web скрапинг. И мы отработали пункт №1, получили URL — только все это можно делать программно, без необходимости взаимодействовать в ручную!
Если в браузере выбрать «посмотреть код страницы», откроется HTML версия нашей страницы, которую необходимо сохранить для дальнейшего взаимодействия.
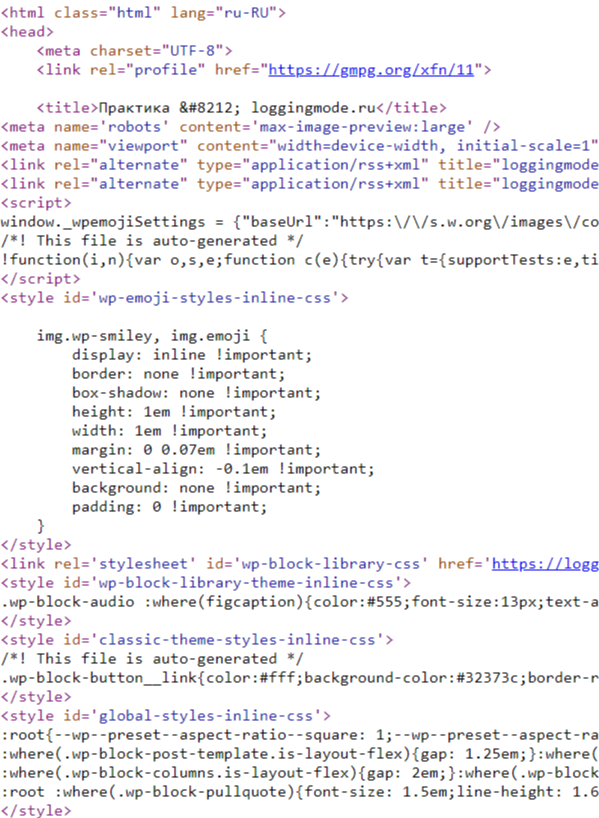
Сама страница представляет структуру блоков, по которым можно пройти и собрать необходимые данные. Как в ручную, так и в автоматическом режиме.
Момент сохранения HTML страницы у себя и называется парсингом, и не важно как вы это сделали! Все что остается — определить, какие данные необходимы, выбрать или написать алгоритм который будет работать конкретно с этой страницей.
Этапы парсинга.
Для начала мы должны определиться, что и как мы будем парсить! Вариантов у нас очень много. Самые распространенные — это проход по интернету через поисковик с дальнейшим погружениям в URL адреса полученные в выдаче, получение данных из конкретного веб сайта.
Анализируем структуру web ресурса для возможного прохода по блокам с информацией которая нам нужна. Здесь следует отметить, что именно нам нужно? Получить список всего контента с сайта, или получение свежих записей.
Если нам нужна вся информация с сайта, то перед тем, как заряжать танк на муху, нужно проверить наличие ленты контента — речь о которой пойдет ниже. Если таковая отсутствует то смело готовим артиллерию, но!
Вся сложность всего процесса заключается в современном подходе проектирования веб сайтов. В далеких нулевых все сайты состояли из стандартной структуры отображения контента и имели иерархию страниц, которые спокойно можно перебирать в алгоритме без костылей.
На текущий момент современные технологии позволяют подгружать страницы или статьи в динамическом режиме, т.е. Отображать 5 — 7 статей на странице, и как только пользователь использует скролл, добавить еще несколько статей / товаров. Так же встречаются сайты с кнопкой в конце страницы «Загрузить еще» после нажатия на которую подгружаются дополнительные модули с контентом.
Если нам нужно получать обновления контента с сайта, то необходимо проанализировать блоки в которых лежат данные и на основании этих блоков, производить парсинг.
Следует отметить что второй вариант осуществляется быстрее и проще.
Формируем алгоритм исходя из наших потребностей и сохраняем информацию у себя в доступных форматах: json, csv, excel, или передаем в Database.
Преимущества и недостатки веб скрапинга.
Скрапинг дает ряд преимуществ и является мощным инструментом, для конкретных задач.
Если посмотреть любую фриланс биржу то обязательно увидим множество специалистов которые за $, готовы заняться парсингом интересующего вас проекта. Выходит скрапинг — это не только инструмент, но и целое направление в области it!

Законность скрапинга.
Один из разрешенных методов это интегрирование RSS ленты. Я думаю все видели блоки с новостями на разных сайтах, при этом новости порой идентичны. Не ужели все парсят информацию с одного источника и не боятся нарушений авторского права? На самом деле нет! Все дело в RSS ленте, она представляет собой некий файл, который позволяет роботам поисковиков получать доступ к статьям вашего сайта и быстро их индексировать, лента имеет XML формат и ее пример мы видим ниже:
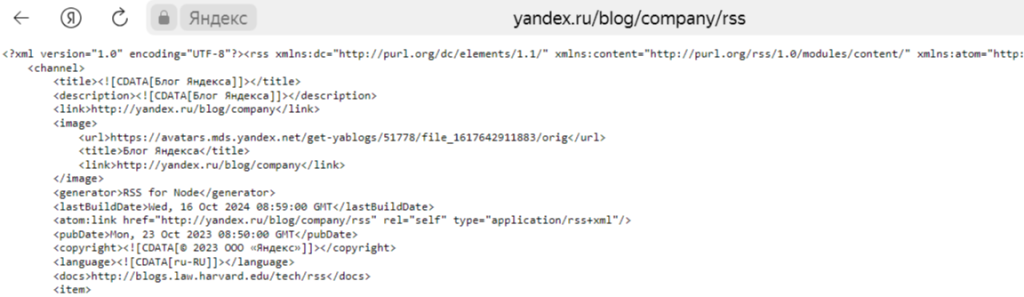
Иными словами RSS лента — это файл в котором содержатся ссылки на все статьи вашего ресурса! А вот давать этот файл другим пользователям или нет — решать уже вам! Если ресурс предлагает такую возможность, написать алгоритм обхода по такому сайту становится проще:

Для чего может потребоваться RSS лента? Например, вы ведете блог по новостной тематике и вам нужно удержать пользователя, вы интегрируете в одном блоке RSS ленту одного ресурса, а во втором блоке — другого. Тем самым, вы позволяете получить пользователю информацию из разных новостных порталов в одном месте! Вот обычный вариант законного парсинга. Достаточно в блок на вашем сайте или приложении внести готовый скрипт:
Вот пример скрипта RSS ленты от Яндекс для WordPress:
<div class="rss-feed" id="rss-feed">
<h2>Новости Яндекса</h2>
<ul id="rss-list"></ul>
</div>
<style>
.rss-feed {
border: 1px solid #ccc;
padding: 10px;
margin: 10px 0;
max-width: 600px;
}
.rss-feed h2 {
font-size: 1.5em;
}
</style>
<script>
async function fetchRSS() {
const rssUrl = 'https://yandex.ru/blog/company/rss';
const response = await fetch(rssUrl);
const str = await response.text();
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(str, "text/xml");
const items = xmlDoc.querySelectorAll("item");
const rssList = document.getElementById("rss-list");
rssList.innerHTML = '';
items.forEach(el => {
const title = el.querySelector("title").textContent;
const link = el.querySelector("link").textContent;
const li = document.createElement("li");
li.innerHTML = `<a href="${link}" target="_blank">${title}</a>`;
rssList.appendChild(li);
});
}
fetchRSS();
setInterval(fetchRSS, 60000);
</script>
Написано конечно красиво, но давайте посмотрим
что мы имеем? А по факту мы видим только новостные темы этого ресурса, которые подкреплены ссылками на первоисточник! Т.е. у нас есть блок с RSS — лентой другого источника и если пользователь нажмет на новость, которая его заинтересовала, мы потеряем его, так, как он перейдет на web ресурс который предоставил нам возможность интеграции со своим сайтом. Хороший способ маркетинга и привлечения трафика. От части с этим можно поработать, но с более сложной схемой перегона трафика между своими сайтами если у вас их несколько. Либо для привлечения трафика с других ресурсов которые разместят у себя блок с вашим списком. Но эта тема другой статьи.
А теперь рассмотрим важные аспекты законности скрапинга.
Один из них и самый главный — вы получаете чужой контент! И тут следует учитывать факт нарушения правовых норм! На сегодняшний день, нет четкого понятия законности и нарушения в скрапинге, как и самого закона по регулировании данного процесса.
Все разделились на два лагеря, в одном приписывают прямое нарушение, в области использования контента, которое регулируется авторским правом, но не могут четко сформулировать в чем заключается само нарушение, так как скрапинг направлен на получение информации, а не способ приватизации контента себе. Другие же уверяют, что скрапинг безвредный и не нарушает закона, используя его в определенных рамках, но точных рамок безнаказанности не существует!
Если сказать более узко, то пользоваться скрапингом или нет, решать только вам, учитывая, что всю ответственность за свои действия вы берете на себя!
Ценовая политика развешенного скрапинга.
Мы уже касались темы, когда нам разрешен скрапинг. Но я напомню: когда ресурс предлагает нам подключение к API своего сервера, для законной отправки запросов и получения информации! Отсюда появляется следующий недостаток:
Вот например API поисковых запросов от Яндекс:
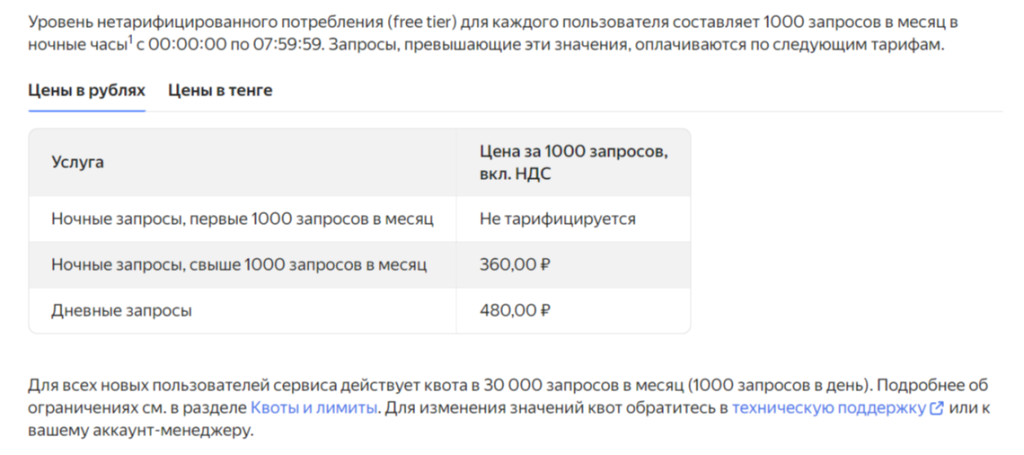
Цены кусаются практически на все услуги it компаний. А обход данной системы опасен блокировкой!
Заключение.
Скрапинг — это полезный инструмент, применяемый в различных сферах, включая веб-разработку и ведение блогов. Он позволяет анализировать структуру сайтов, выявлять блоки с данными, понимать логику страниц и частоту использования тегов. Также с помощью навыков скрапинга можно защитить свой ресурс от нежелательного парсинга. Кроме того, скрапинг помогает быстро перенести информацию с одного проекта на другой.
Однако стоит отметить, что применение этого инструмента требует серьезных усилий, особенно при сборе больших объемов данных с разных источников.
Важно помнить, что все действия должны осуществляться в рамках закона и не должны нарушать авторские права.